Sid Singaravel

Graduate Analytics @ Northeastern, MA
Previously, Data Science @ Fidelity, ZoomRx
Otherwise - cooks, runs, fantasy football.
📧 singaravel dot s at northeastern dot edu
LinkedIn | GitHub | Substack | Tableau
📄 View my résumé
Select Projects
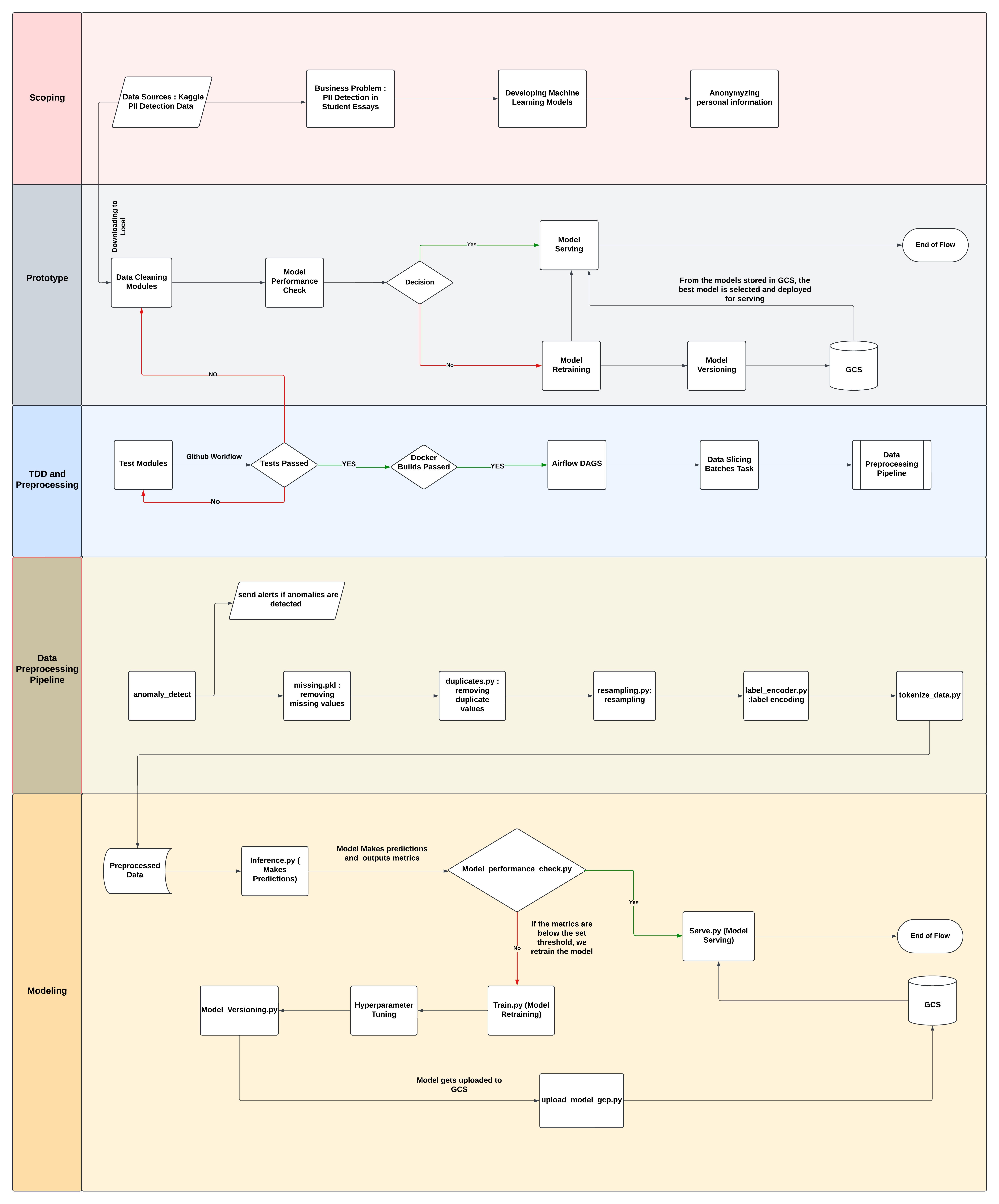
Detecting Personally Identifiable Information (PII) in Student Writing
- End-to-end Machine Learning (MLOps) pipeline to detect compromising student information in their academic writings. Cron-scheduled CI/CD pipelines incorporated to auto evaluate and finetune for the incoming feature vectors.
- Tools: DVC, Elasticsearch, Logstash, Kibana, Tensorboard, Tensorflow, Airflow, MLFlow, HuggingFace (fetching pretrained models), Python
[code]
MetFaces: Latent Diffusion Image Synthesis
- Developed and optimized a diffusion-based generative model using a modified U-Net architecture for art-styled facial image synthesis, leveraging the MetFaces dataset (1,336 images). Conducted comparative analysis of linear and cosine noise schedules, achieving a 15% improvement in Fréchet Inception Distance (FID) scores with the cosine schedule
- Optimized diffusion-based generative model training for art-styled facial image synthesis using NVIDIA RTX 3060 GPU with CUDA acceleration, achieving FID scores under 30. Implemented hyperparameter tuning with Hyperopt and experiment tracking via MLflow
[report]

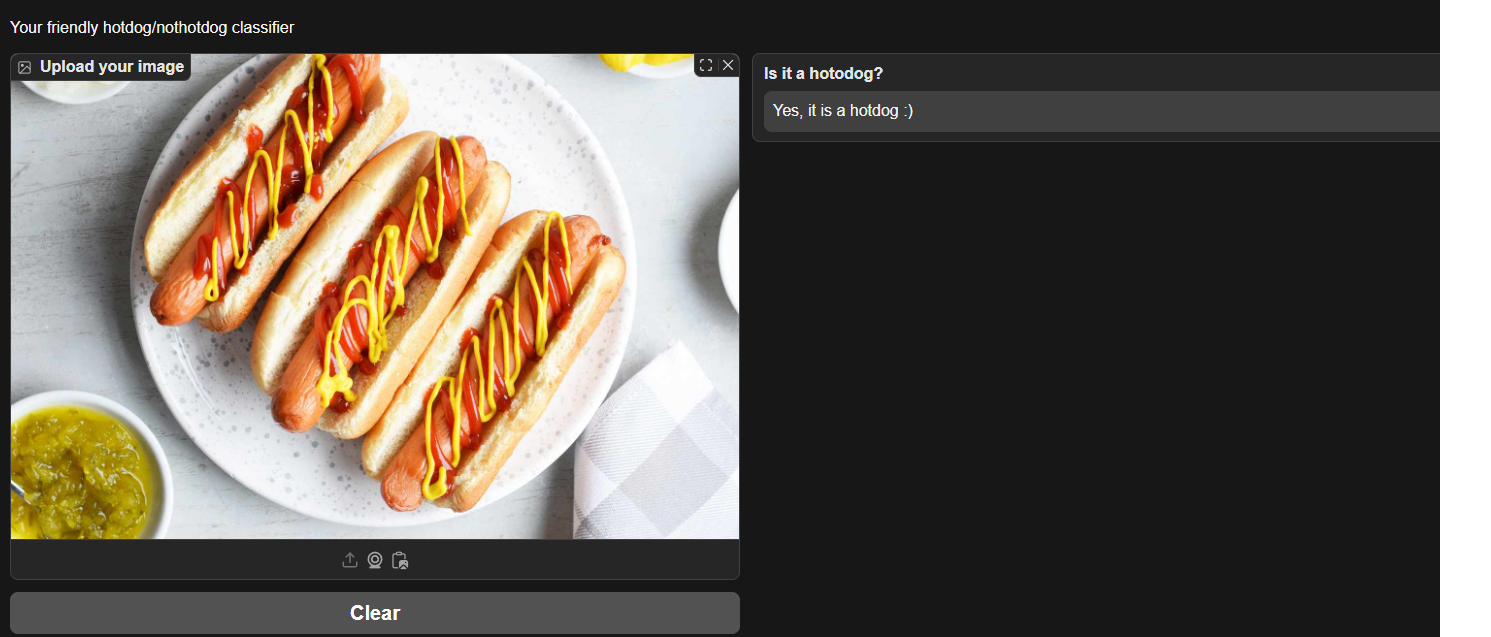
🌭 Hotdog/Not Hotdog ResNet18-powered Image Classifier
- Inspired by Jian Yang’s (Silicon Valley) stellar idea, built a ResNet18-powered image classification model in PyTorch, fine-tuned for binary (hotdog/not hotdog) classification.
- Deployed the model via Gradio on Hugging Face Spaces (stashed the model in LFS), allowing users to interact with the model directly by uploading
[huggingfaces gradio app] [code]
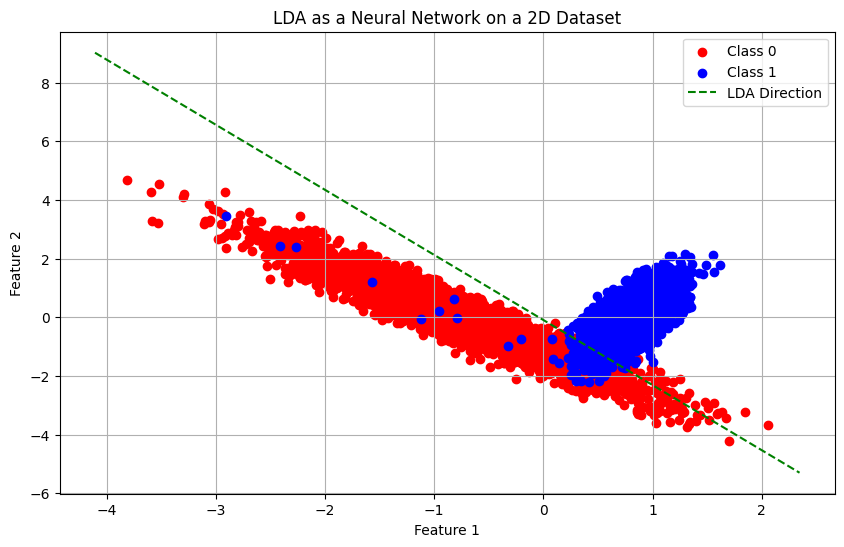
Linear Discriminant Analysis - A Comprehensive Guide
- A deep dive into the mathematical underpinnings and the statistical assumptions that make LDA a powerful dimensionality reduction and classification tool
- Reformulating LDA as a Neural Network: Discover how LDA can be reimagined as a Neural Network classifier, implemented as a simple Multilayer Perceptron (MLP) trained using backpropagation
[substack blog] [report]
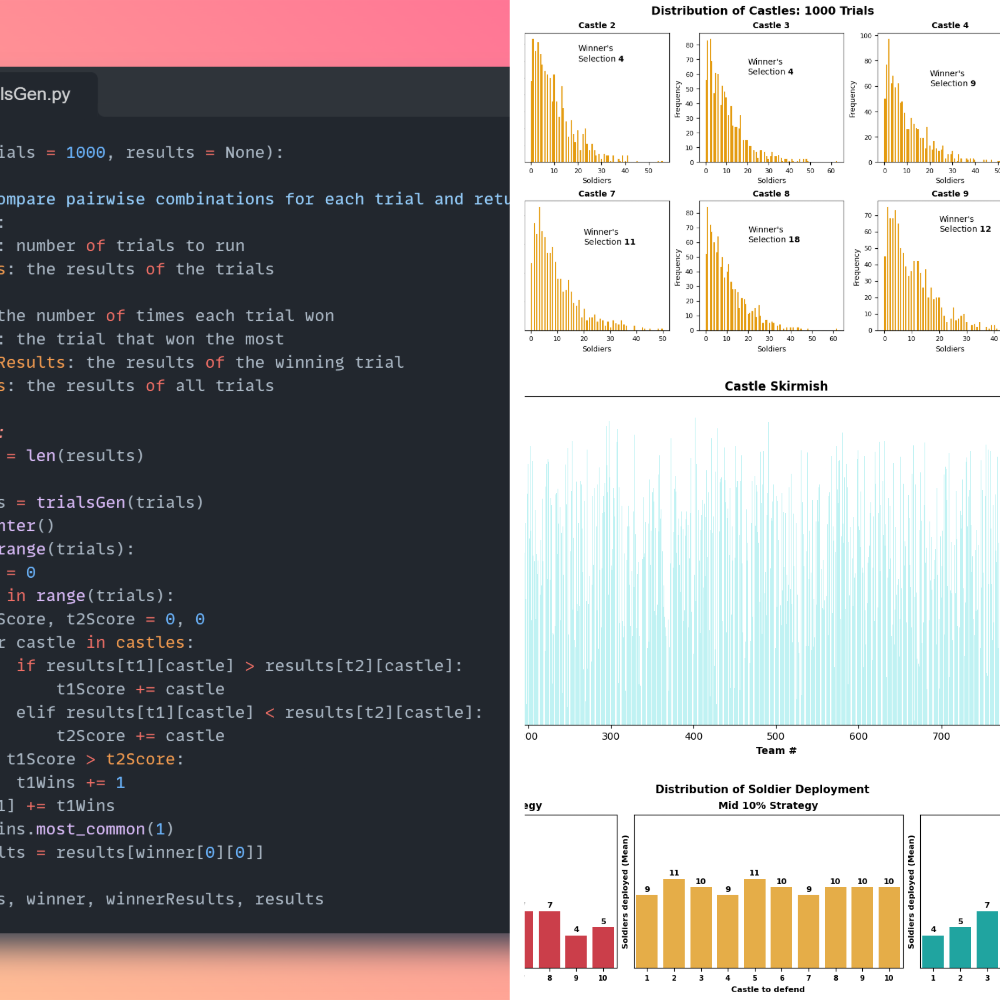
Monte Carlo Strategy for FiveThirtyEight’s Riddler Nation
- Developed a Monte Carlo-based simulation strategy to optimize soldier deployment in FiveThirtyEight’s Riddler Nation, refining approaches through randomized trials and pairwise evaluations
[substack blog]
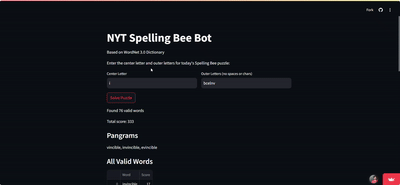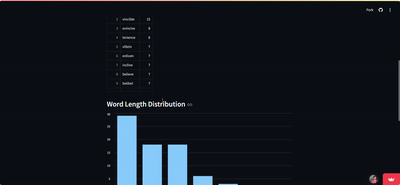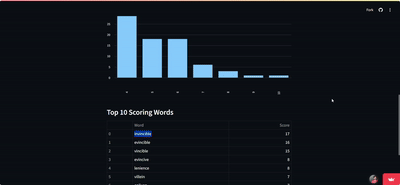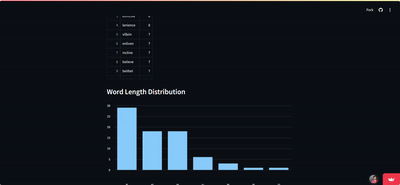
BeeBot: NYT’s Spelling Bee Solver
- Engineered a high-performance solver for the NYT Spelling Bee puzzle, processing 170,000+ words in under 1 second
- Developed an intuitive Streamlit web interface, enabling users to input puzzle parameters and receive instant results, including valid words, pangrams, and score distributions
[beebotnyt.streamlit.app]
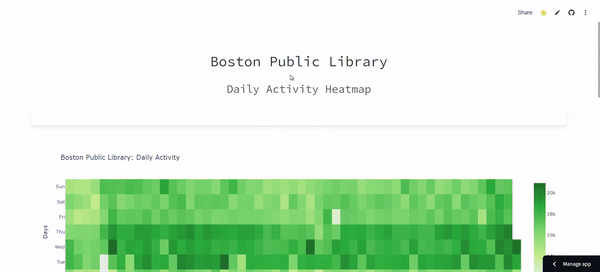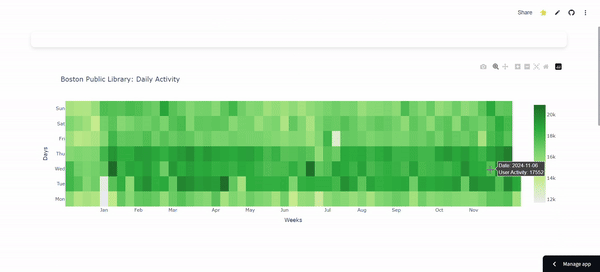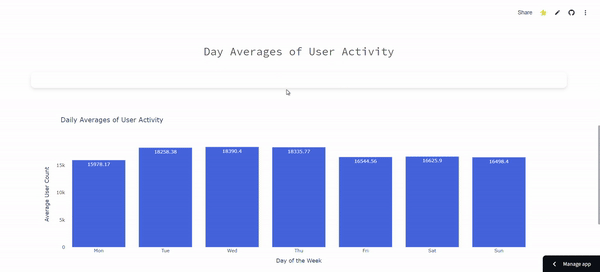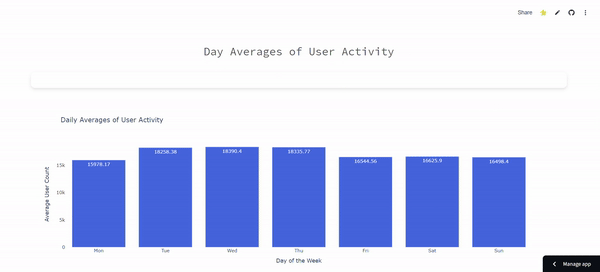
ETL Pipeline for Tracking Boston Public Library Daily Activity: Cron-Scheduled Reporting
- Automated Data Pipeline: Implemented a cron-scheduled pipeline to collect and process Boston Public Library user activity data daily, using Python, Pandas, and Plotly for real-time visualizations.
- Data Aggregation & Visualization: Engineered data aggregation with Pandas and interactive visualizations with Plotly, automating daily updates via cron for consistent reporting.
- Data Source: Analyze Boston, Boston Public Library [link]
[bostonpubliclibrary.streamlit.app] [code]
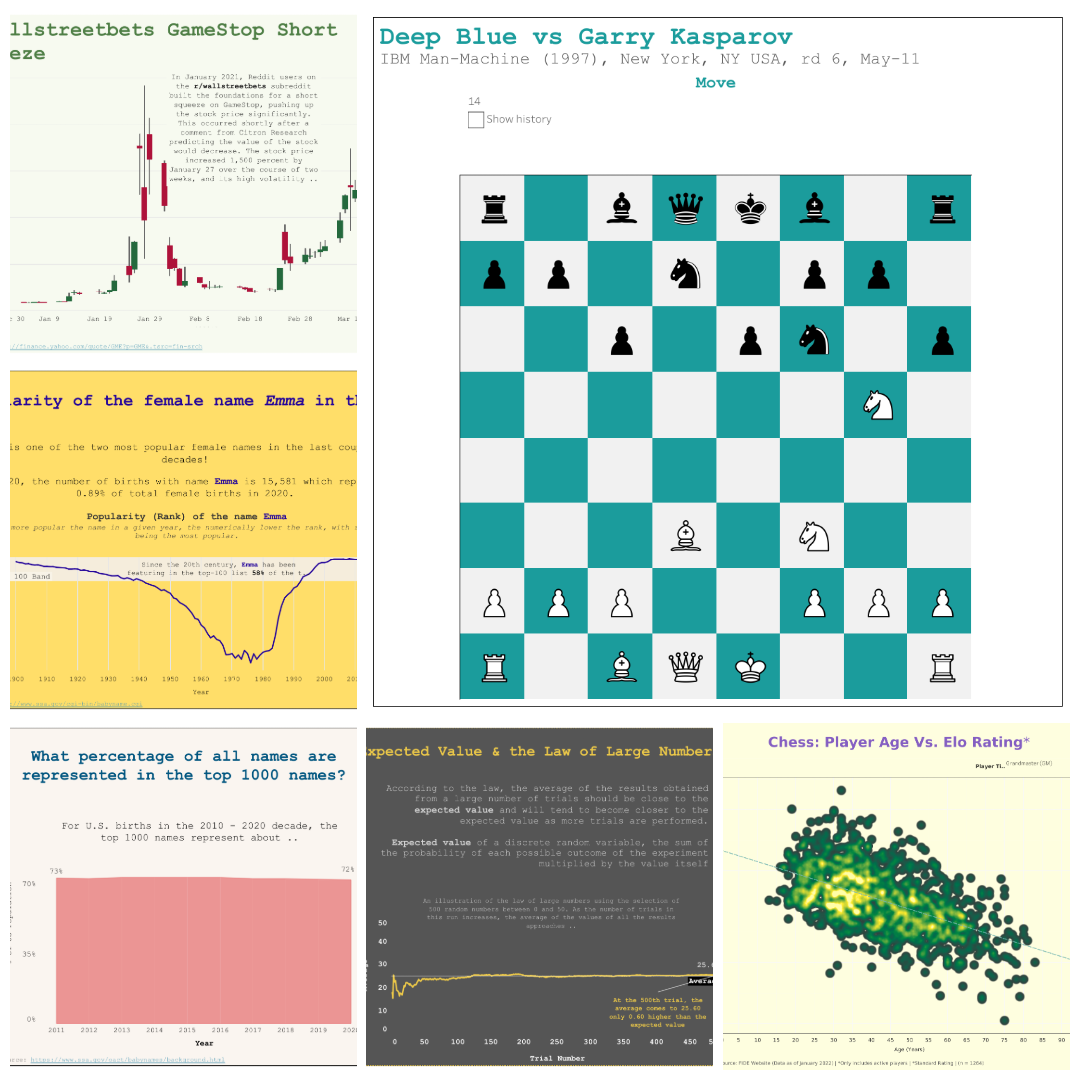
Project Visualization: Tableau
Played around with some quirky datasets in Tableau, including:
- A move-by-move visualization of the epic 1996 chess showdown between Deep Blue and Kasparov (yeah, when AI first beat a human chess champion!)
- Tracked how the name “Emma” became a total hit for baby girls in the US over the years (spoiler: it really took off!)
[Tableau Public Profile]
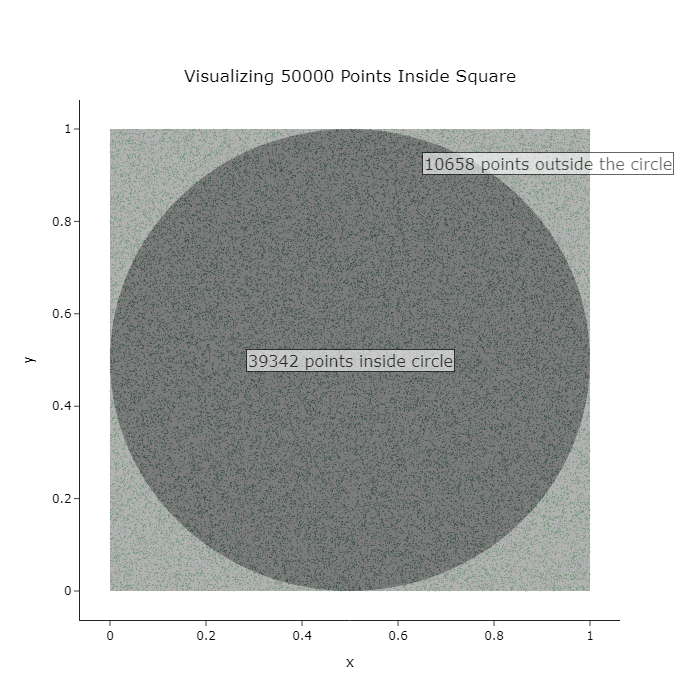
Estimating Pi through Monte-Carlo Methods
- Developed a Monte Carlo simulation using random point sampling in a unit square to estimate π. Generated 1M+ random (x,y) coordinates and calculated the ratio of points falling inside a quarter circle to total points, achieving a 3-digit precision estimate of π ≈ 3.141.
- Implemented statistical convergence analysis using the Law of Large Numbers, demonstrating how increasing sample size improves estimation accuracy. Visualized convergence patterns through matplotlib animations, showing error reduction from 10% to <0.1% with increased iterations.
[substack blog]
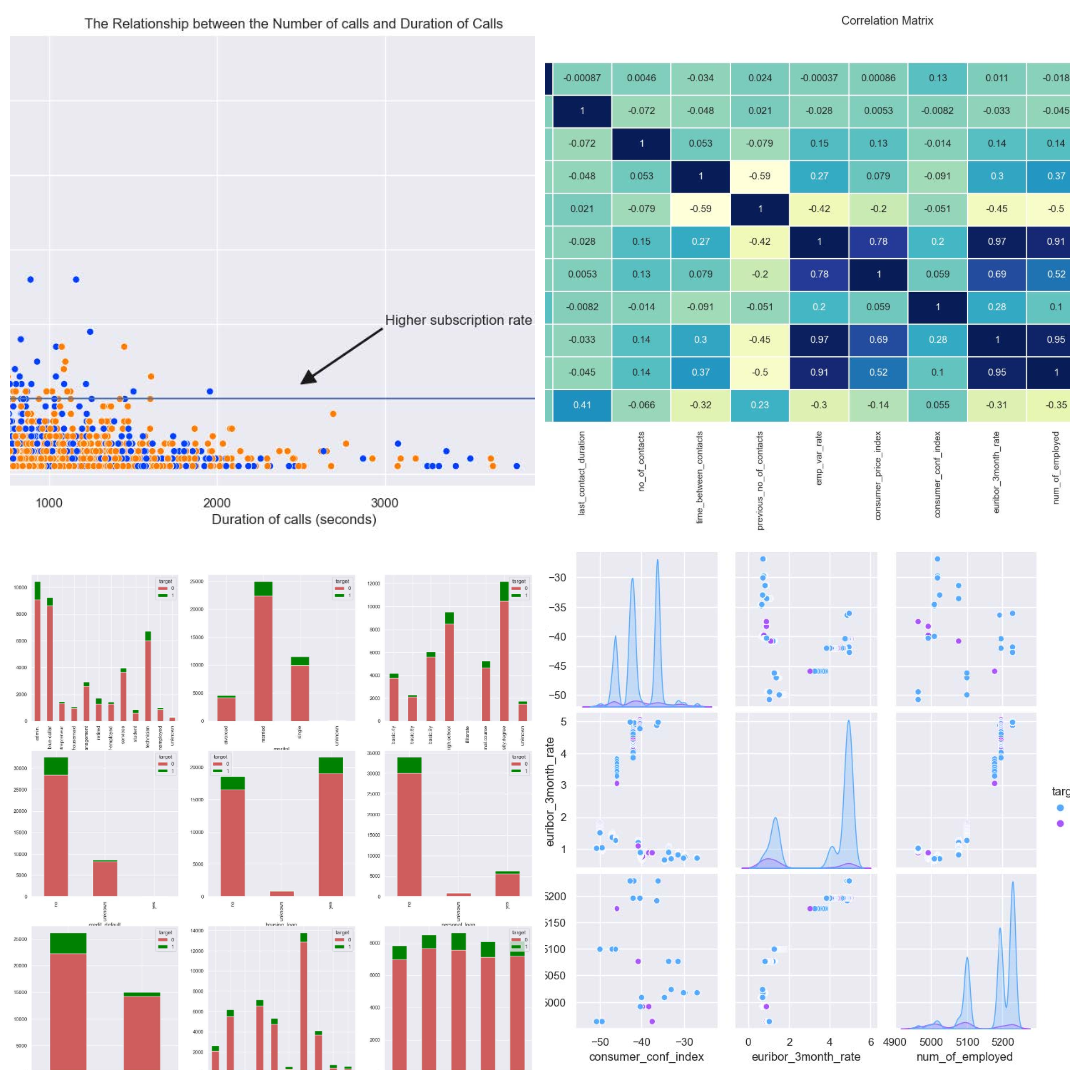
Banking Behavior Analytics: Predicting Term Deposit Subscriptions
- ML Pipeline Development: Built predictive models analyzing 41,188 marketing campaign records to forecast term deposit subscriptions. Implemented SMOTE and ADASYN for handling class imbalance, achieving 97% accuracy with k-NN (k=2). Used Logistic Regression, k-NN, and SVM classifiers with cross-validation for model evaluation.
- Feature Engineering & Analysis: Engineered 20 features including client demographics, macroeconomic indicators, and campaign metrics. Revealed key demographic insights through exploratory analysis: young professionals showed highest subscription rates, and cellular contact campaigns demonstrated 10x better conversion rates. Utilized correlation analysis and dimensionality reduction techniques (PCA) for feature selection.
[report]
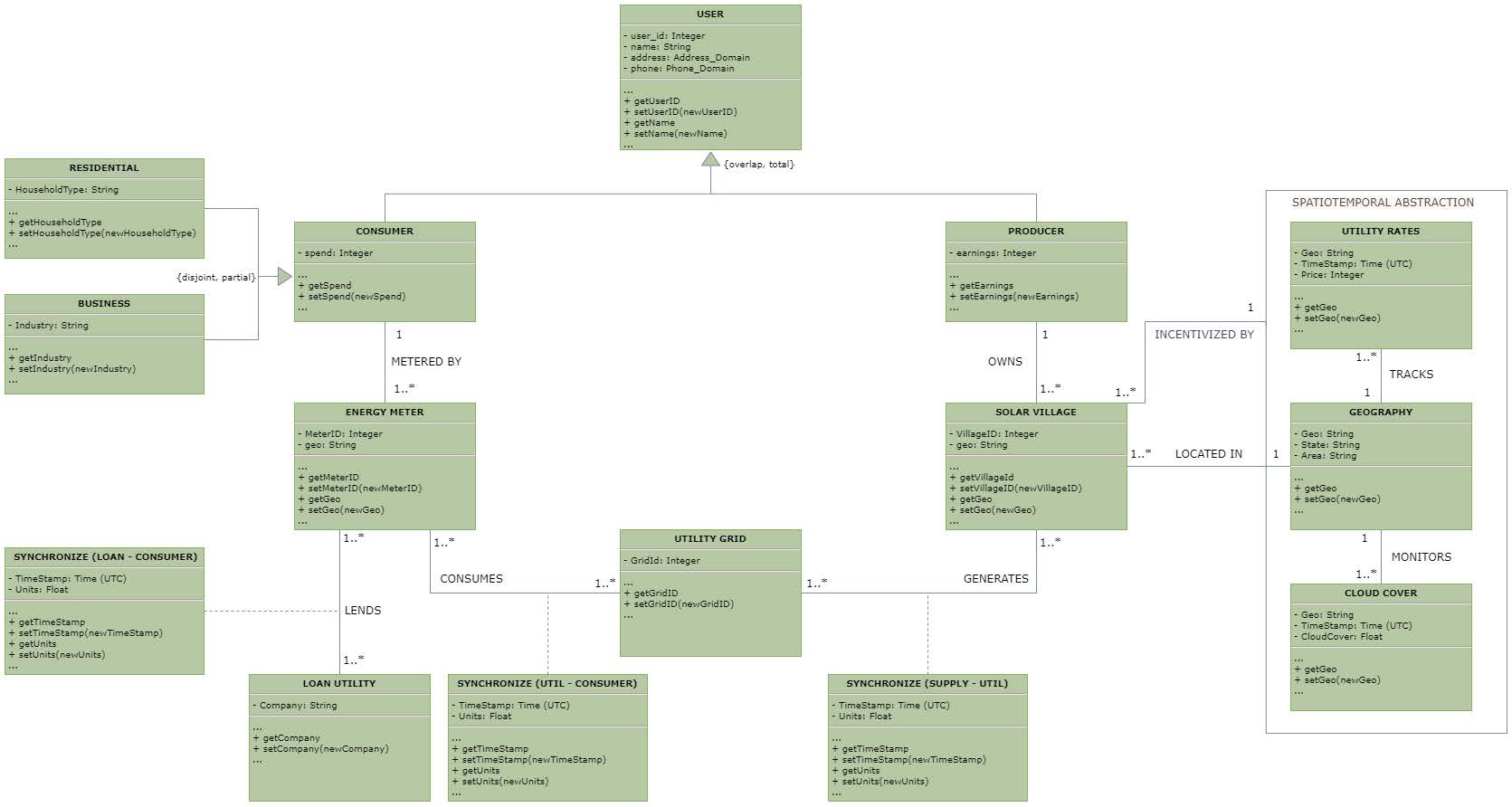
Database Design for Clean Energy Market Operation
- Built a centralized database system for tracking residential solar grid metrics and user behavior
- Used MySQL and Neo4j (graph) for data modeling, with Python-based visualization through Streamlit. The system calculates producer incentives based on energy contributions to utility grids
- Architected UX interface for real-time analytics using Python-SQL driver (PyMySQL) and Streamlit API
[report]
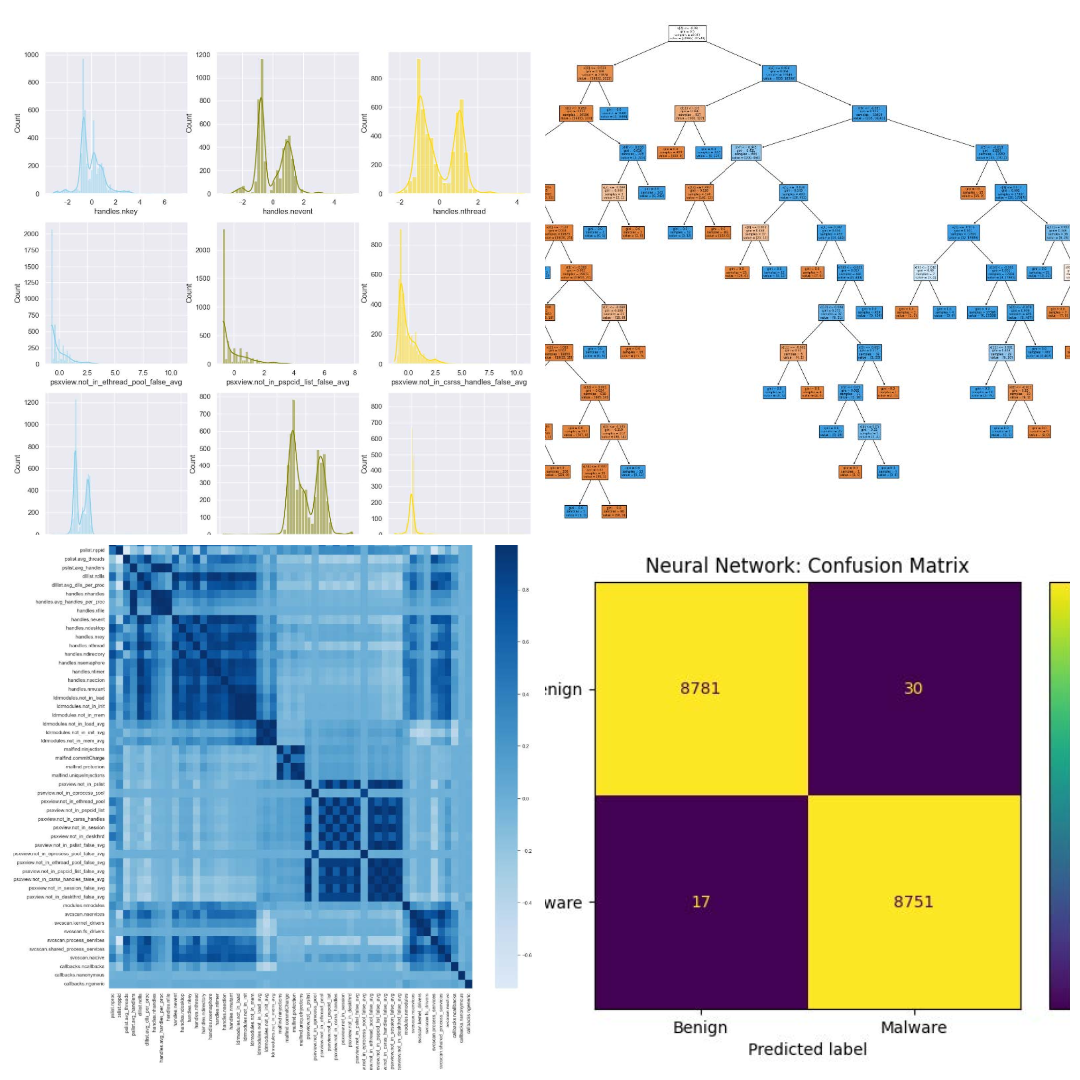
Obfuscated MalMem: Sophisticated Malware Detection through Supervised Learning Strategies
- Built an array of classification models analyzing 59,000 memory dump records to detect sophisticated malware. Implemented feature engineering and dimensionality reduction (PCA) on 55 features, reducing to 15 components while retaining 97% variance. Achieved 99.98% accuracy using SVM and k-NN classifiers, with near-perfect precision scores.
- Developed correlation analysis to reduce feature dimensionality, implementing high covariance filters (threshold 0.90) to eliminate 29 redundant features. Evaluated six ML models including Logistic Regression, k-NN, Decision Trees, Random Forest, SVM, and Neural Networks, optimizing for both accuracy and computational efficiency.
[report]
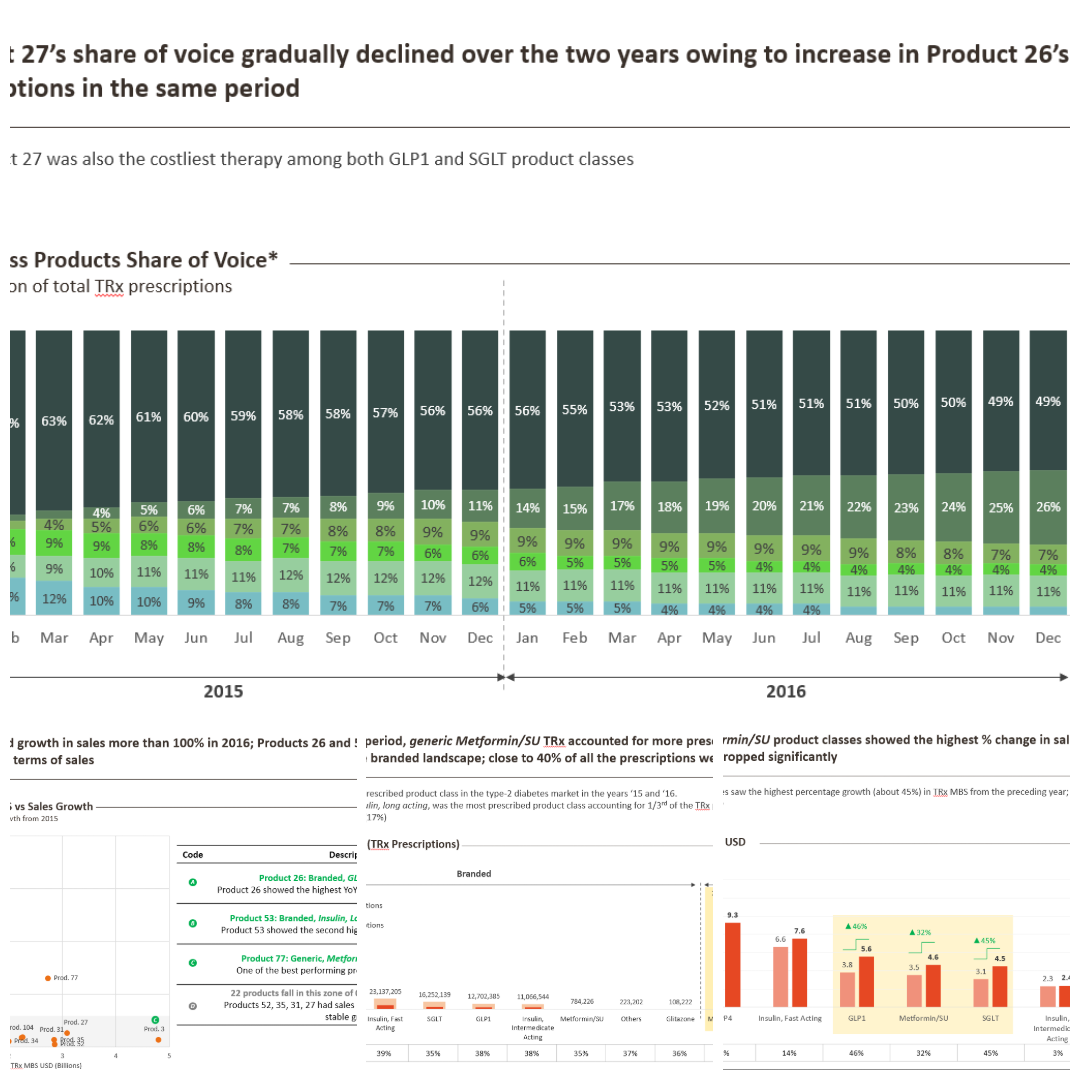
Market Analysis: Strategic Insights for a Type-2 Diabetes Drug Launch
- Performed market analysis for a hypothetical Type-2 Diabetes drug launch, assessing branded vs. generic dynamics, sales trends, and competitor pricing strategies
[slide deck]
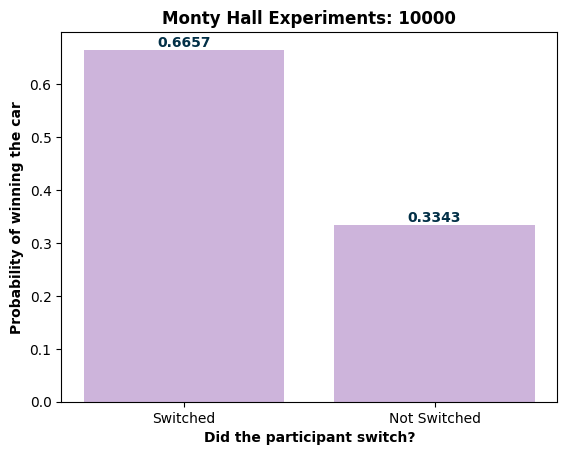
Always Switch: Monty Hall Monte Carlo Simulations
- Developed a Python simulation of the Monty Hall Problem, conducting 10,000 trials to demonstrate the counterintuitive probability concept, resulting in a 67.4% win rate when switching doors
- Created data visualization using matplotlib to clearly illustrate simulation results, enhancing understanding of complex probability principles through visual representation
[link]
Two Chords Intersecting: What are the chances?
- This Monte Carlo simulation explores the probability of two randomly drawn chords intersecting within a unit circle. The experiment generates random chords and determines whether they intersect, repeating this process 10,000 times to estimate the probability empirically.
- As the trials accumulate, we converge on an empirical probability, offering insight into this geometric phenomenon. This experiment not only demonstrates the power of Monte Carlo methods in solving complex probabilistic problems but also reveals the hidden patterns within seemingly random geometric configurations.
[link]

Page template forked from evanca